Hej! Chciałbym w tym wpisie poruszyć temat optymalizacji naszych ukochanych aplikacji. Większość porad może znaleźć tutaj odzwierciedlenie jedynie w web aplikacjach, ale w dalszym ciągu zachęcam do lektury. Nie wiem jak Wy, ale ja lubię gdy strony WWW działają szybko – na tyle szybko, abym nie musiał rozmyślać nad losami świata pomiędzy ładowaniem kolejnych podstron. Sposobów optymalizacji, podejść do optymalizacji mamy tutaj nieskończoność. Niektóre oczywiście są lepsze – inne gorsze. Jeżeli mnie nuda nie zabije, to powstanie tutaj seria wpisów związanych z tym ciekawym tematem w oparciu o moje doświadczenia i historie z którymi się spotkałem w ostatnim czasie.
Aktualne nasze spotkanie poświęcę na temat tego co w ogóle warto optymalizować i kiedy to robić. Nie wiem na ile jest Wam znana książka „DevOps Handbook”, ale została tam wdrożona ciekawa teoria związana z ograniczeniami nam stawianymi. Tak naprawdę jest ich wiele poziomów i dopóki tych pierwszych nie odblokujemy, nie powinnismy iść dalej. Czyli tak naprawdę należy skupić się na problemach, które są największe i ich usunięcie da nam najwięcej korzyści.

Poszukiwania bottlenecków
W jaki sposób podejść do znalezienia miejsc w aplikacji, które zasługują na naszą uwagę? Warto zbierać metryki – wiem, że brzmi to nudno i przecież widzimy swój kod – to po co jeszcze na jego temat zbierać jakieś informacje?! Uwierzcie mi, że to się odpłaci z nawiązką. Jakieś dwa lata temu zbudowałem narzędzie, które monitoruje użycie konkretnych części aplikacji, by później na tej podstawie generować raport miejsc z martwym kodem. Wszystko fajnie – trupy znajdowaliśmy dzięki temu w łatwy sposób, zarówno nieużywane kontrolery, szablony widoków czy masa innych informacji. Ale… Pewnego dnia zostałem oświecony i zrozumiałem, że przecież mogę tego narzędzia użyć również w inny sposób. Jaki? Zacząłem analizować, które miejsca są najczęściej używane – na przykład kontrolery Symfony (taki framework Web MVC php). Zauważyłem, że wiele z nich jest używanych niesamowicie często. Teraz uwaga – skupcie się – kojarzycie zasadę Pareta (parreto principle)? Traktuje ona w tym przypadku, że 20% najczęściej używanych kontrolerów odpowiedzialnych jest za 80% całego ruchu. Tak też było – jeżeli skupimy się na tych miejscach, które otrzymują 20% requestów HTTP – zyskamy bardzo dużo. Gdybyśmy zabrali się nawet za najwolniejszy endpoint świata, który jest rzadko używany – nie mielibyśmy tak dużego wzrostu ogólnego APDEX.
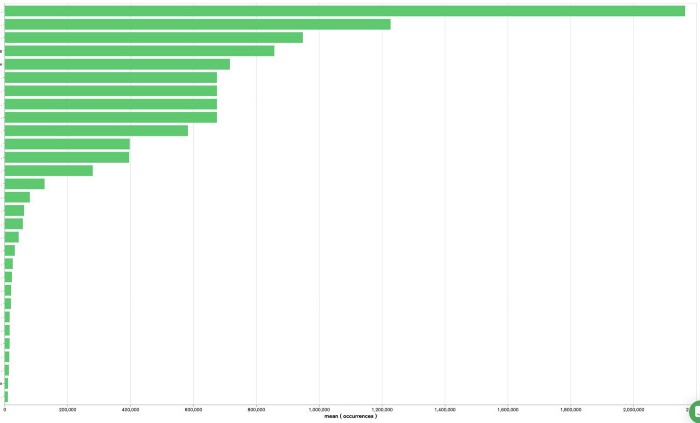 Najczęściej używane endpointy w ciągu 24h w jednej z aplikacji (ukryłem nazwy :P)
Najczęściej używane endpointy w ciągu 24h w jednej z aplikacji (ukryłem nazwy :P)
Jak widzicie na powyższym wykresie – niektóre miejsca są znacznie częściej używane od innych. Także skoro tak bardzo walczą o naszą atencję – przyjrzyjmy się im. :) Ja w tym przypadku uciąłem jednym magicznym trickiem liczbę requestów z 2.4mln dziennie do poziomu około niecałych 75tys dziennie. W kolejnych wpisach opowiem o tym więcej.
Podobne metryki możecie również rejestrować za pomocą rozbudowanych narzędzi typu NewRelic – mamy zakładkę transakcji, które przechodzą przez cykl życia naszego systemu i tam w łatwy sposób znajdziemy miejsca obciążone największym ruchem. Znajdziecie tam nawet możliwość sortowania użyć elementów aplikacji po największym throughput-cie – co jest niesamowicie wartościowym wskaźnikiem w naszych cudownych poszukiwaniach.
Jak weryfikować?
Gdy już znajdziemy miejsca, które zasługują na to aby zostały przez nas dopieszczone – warto przyjrzeć się im bliżej. Tutaj z pomocą przychodzą nam przeróżne profilery. Jeżeli pracujecie z NewReliciem to jesteście w stanie zobaczyć w nim wiele ciekawostek, które Was mogą zainteresować. Transakcje, o których pisałem, zawierają także rubrykę ze szczegółami tego co dzieje się w aplikacji podczas wykonywania cyklu request-response. Jak w przypadku profilerów – możemy tutaj znaleźć między innymi czasy wykonywania poszczególnych elementów kodu, zapytania SQL, które robimy do naszej bazy i podobne. Taka sugestia: zwróćcie uwagę na to czy jakieś metody w systemie nie są uruchamiane wielokrotnie w jednej transakcji. Można tam czasami znaleźć elementy systemu, które robią jakieś operacje w pętli – co za tym idzie, możemy często łatwo to zmienić w preloading i wyciąganie informacji przed operowaniem na nich. W takich sytuacjach poprawnie optymalizując oszczędzimy na pewno zarówno dużo czasu, jak i zmniejszymy obciążenie bazy danych. Warto także odwiedzić rejestr zapytań SQL, które wykonujemy, przyjrzeć się tym najwolniejszym czy najczęściej wykonywanym. Możemy tutaj dowiedzieć się naprawdę dużo na temat tego, które elementy naszego systemu stwarzają problemy z punktu widzenia na przykład naszego systemu RDBMS.
Cache, cache everywhere
Na niejednej konferencji związanej z tematami programowania temat cache-u był poruszany raczej wyśmiewczo. „Zoptymalizuj swoje operacje, nie cache-uj” – wielokrotnie słyszałem tego typu słowa. Oczywiście jest w nich cholernie dużo racji, ale w pewnym momencie dojdziemy do sytuacji, gdzie sama poprawa wydajności wykonywania obliczeń, operacji I/O itd nie wystarczy. Wtedy warto rozważyć właśnie pamięć podręczną. Są miejsca w aplikacji, gdzie nasz użytkownik końcowy jest gotowy na to, że dane, które widzi mogą pochodzić sprzed chwili – wykorzystajmy to (z głową!). W jednym z wpisów postaram się poruszyć bardzo ciekawy temat cache-owania na poziomie całego requestu z użyciem na przykład Varnisha i jak dużo jesteśmy w stanie dzięki temu ugrać z naszego ruchu, który nie musi nawet docierać do naszej aplikacji. Przy okazji warto przypomnieć tutaj jedną ze złotych myśli IT: „w programowaniu dwie rzeczy są trudne: inwalidacja cache-u i nazewnictwo”. Także jak już będziemy pracować nad wrzucaniem różności do pamięci podręcznej weźmy też pod uwagę sposób w jaki będziemy później inwalidować te informacje.
Mikrooptymalizacje
Czy mają one sens? W większości przypadków nie, chyba że pracujemy nad systemami o niesamowicie dużym ruchu jak Netflix, Facebook itd. (założę się, że 99% osób czytających ten wpis nie pracuje przy czymś takim). Często takie mikrooptymalizacje to zmiany w zużyciu procesora o pare opcode-ów, więc na luzie nie musimy o tym super poważnie myśleć. Oczywiście robienie takich rzeczy już w samym naszym nawyku jest w porządku, ba – nawet super w porządku. Jeśli jednak chcemy wykonywać iteracje na jakimś kodzie tylko po to by ugryźć takie mikro różnice – odpuśćmy sobie, wypijmy w tym czasie dobrą kawę a tę zdobytą i oszczędzoną energię poświęćmy na coś bardziej owocnego w widoczne rezultaty.
Co dalej?
W następnych dniach poruszę temat konkretnych podejść do optymalizacji, sposobów radzenia sobie z konkretnymi typami problemów czy ciekawostkami, które będziecie mogli użyć natychmiast po przeczytaniu kolejnych wpisów.
Przy okazji chciałbym podziękować mojemu koledze Przemysław Robak, który pokazał mi bardzo wiele funkcjonalności NewRelica o których mogłem tutaj napisać. Dzięki za uwagę i do następnego razu. :)